Overview
Surgical implants in spinal X-rays frequently occlude underlying anatomy, posing challenges for clinical interpretation and automated analysis. In this group project, we developed a high-fidelity inpainting approach based on Denoising Diffusion Probabilistic Models (DDPMs) to reconstruct the hidden anatomical structures.
The model was trained entirely on synthetic digitally reconstructed radiographs (DRRs) generated from CT volumes, then evaluated on real clinical X-rays. Using the RePaint inpainting strategy, the DDPM progressively reconstructs missing image regions while maintaining structural consistency.
My contribution: model training, inference pipeline, and all visualizations. The synthetic training dataset was primarily created by other team members.
Iterative Denoising Process
The diffusion model gradually reconstructs coherent anatomical structures from noise. Starting from a fully noisy state, the model iteratively refines the masked region over approximately 1000 timesteps.
.png)
From left to right: masked input, noisy state (t≈1000), intermediate steps (t=100, t=10), and final reconstruction (t=0).
Inpainting on Synthetic Data
Examples of implant removal on synthetic digitally reconstructed radiographs (DRRs). The videos show the iterative reconstruction process from noise to the final anatomically coherent result.
Inpainting Process
Example 1
Example 2
Original X-rays with Masks
Example 1
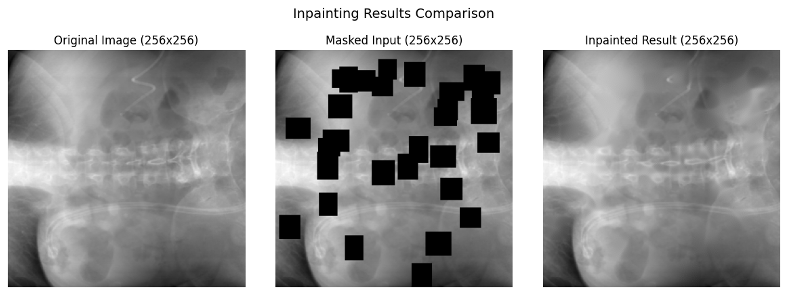
Example 2

Results on Real X-rays
Inpainting results on 10 real clinical spinal radiographs. Each case shows the original X-ray with the masked implant region, our DDPM-based reconstruction, and a standard U-Net baseline for comparison.
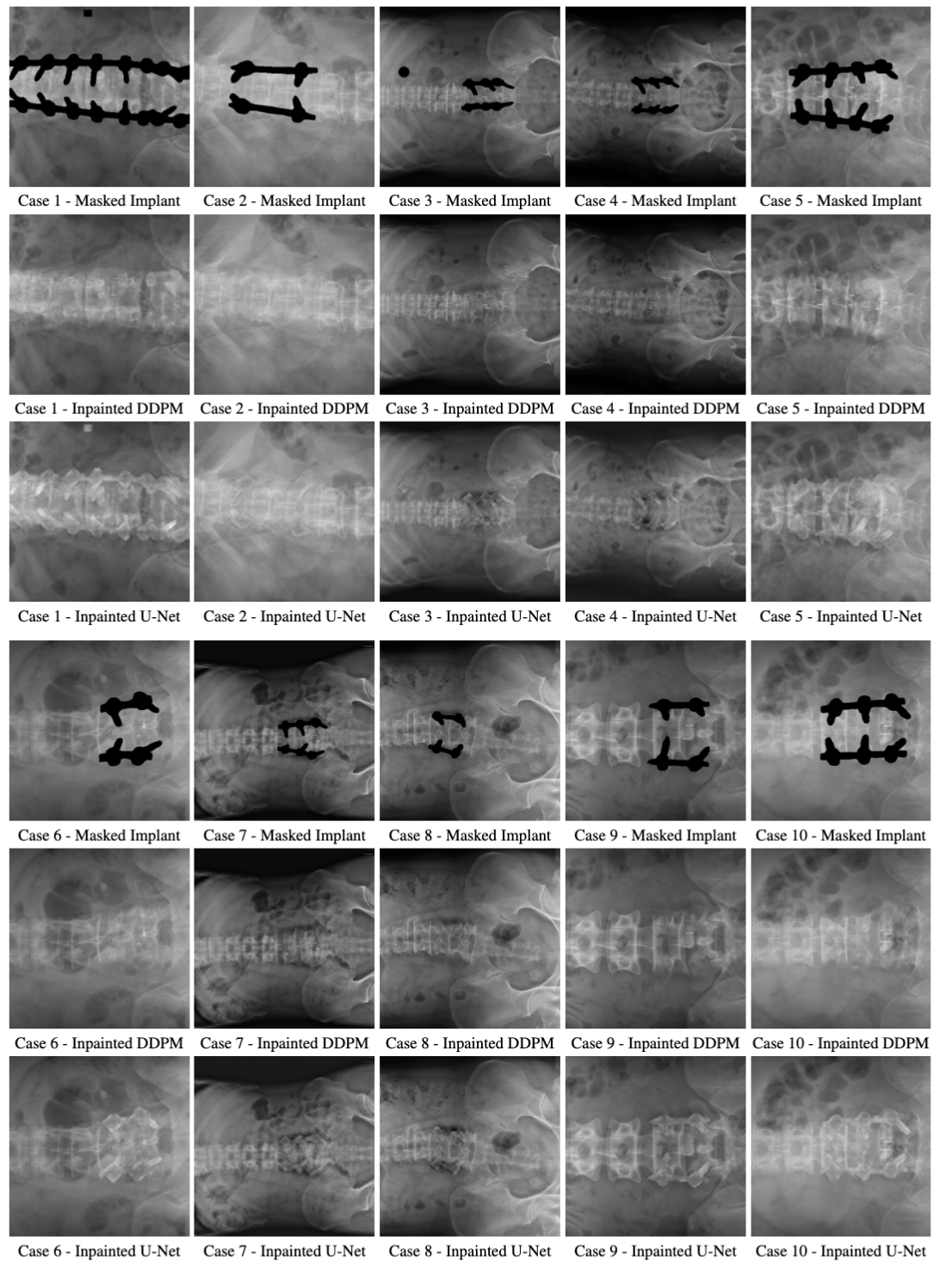
Top row per group: masked implant. Middle row: DDPM inpainting (ours). Bottom row: U-Net baseline. The DDPM produces more realistic anatomical reconstructions with better structural coherence.
Method
We trained a Denoising Diffusion Probabilistic Model on synthetic radiographs generated from CT volumes using the DiffDRR framework. The training dataset consisted of approximately 9,700 DRR images from the VerSe and Spine 1K datasets.
For inpainting, we employed the RePaint algorithm (Lugmayr et al., 2022): during each reverse diffusion step, known (unmasked) regions are replaced by samples from the forward process, while masked regions are generated by the trained model. This enforces consistency with the original image content throughout generation.